NoSQL Profilo
NoSQL (NoSQL = Non solo SQL), che significa "non solo SQL".
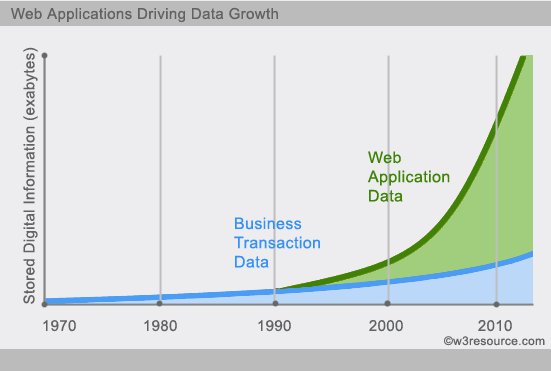
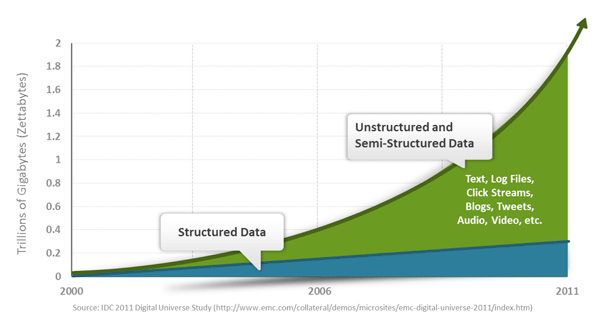
Nei moderni sistemi informatici giorno sulla rete avrà una grande quantità di dati.
Questi dati sono una gran parte del sistema di gestione di database relazionali (RDMBSs) da affrontare. proposto di carta 1970 EFCodd modello relazionale "Un modello relazionale dei dati per le grandi banche dati condivise", il che rende i dati di modellazione e di programmazione delle applicazioni più facile.
Applicando modello relazionale provata è molto adatto per la programmazione client-server, ben oltre i benefici attesi, e oggi è i dati strutturati memorizzati nella rete e applicazioni aziendali tecnologia dominante.
banca dati NoSQL è un nuovo movimento rivoluzionario, in anticipo su di esso è stato suggerito che la tendenza allo sviluppo di sempre più in aumento al 2009. NoSQL sostenitori che promuovono l'uso di memorizzazione dei dati non relazionali, per quanto riguarda l'uso opprimente di database relazionali, questo concetto è indubbiamente iniettato un nuovo modo di pensare.
database relazionale per seguire la ACID regole
operazione inglese è di transazione, e il mondo reale di trading è molto simile, ha le seguenti quattro caratteristiche:
1, A (Atomicità) Atomic <br> atomica facile da capire, che tutte le operazioni di transazione sia tutto fatto, o non fare, la transazione è una transazione le condizioni per il successo di tutte le operazioni hanno successo, finché ci una operazione non riesce, l'intera transazione avrà esito negativo, è necessario eseguire il rollback.
Come ad esempio bonifici, il trasferimento conto da A a B conti 100 yuan, è diviso in due fasi: 1) prendere la contabilità A 100 yuan; 2) per B 100 yuan conti di deposito. Questi due passaggi sono stati completati insieme o non insieme a termine, se completato solo il primo passo, il secondo passaggio non riesce, i soldi in qualche modo 100 yuan di meno.
2, C (coerenza) coerenza <br> coerenza è relativamente facile da capire, che è stato nel database in uno stato coerente, eseguire l'operazione non cambierà i vincoli di coerenza database originale.
Esistenti vincoli di integrità come a + b = 10, se una transazione cambia, si devono cambiare b, in modo che l'estremità posteriore della transazione è ancora soddisfare a + b = 10, altrimenti l'operazione fallisce.
3, I (isolamento) <br> cosiddetta indipendenza significa che l'indipendenza non si influenzano a vicenda transazioni concorrenti, se un dati delle transazioni a cui accedere da un'altra transazione viene modificato finché un'altra transazione senza commit, è i dati si accede non è influenzato dalla transazione commit.
Ad esempio, vi è un conto di trading esistente viene trasferito da A a B conti 100 yuan, nel caso di questa operazione non è stata completata. Se la B controllare i loro conti, non può vedere le appena aggiunti 100 yuan.
4, D (Durability) Persistenza Persistenza riferisce <br> volta che la transazione si impegna, edita saranno memorizzati in modo persistente sul database, non sarà persa anche in caso di inattività.
Sistemi distribuiti
I sistemi distribuiti (sistema distribuito) computers componenti software multiple e del collegamento di comunicazione (rete locale o wide area network) composto da una rete di computer.
I sistemi distribuiti sono costruiti sulla cima di sistemi software di rete. È proprio a causa delle caratteristiche del software, il sistema distribuito con un alto grado di coesione e trasparenza.
Pertanto, la differenza tra la rete e il sistema distribuito che più programmi di alto livello (in particolare il sistema operativo), piuttosto che hardware.
I sistemi distribuiti possono essere applicati su diverse piattaforme come PC, workstation, LAN e WAN e simili.
I vantaggi di calcolo distribuito
Affidabilità (tolleranza ai guasti):
Importanti vantaggi di un sistema di calcolo distribuito è l'affidabilità. Crash un server non influenza il resto del server.
Scalabilità:
In un sistema di calcolo distribuito può aggiungere più macchine in base alle esigenze.
La condivisione delle risorse:
La condivisione dei dati è essenziale per applicazioni quali banche, sistemi di prenotazione.
flessibilità:
Poiché il sistema è molto flessibile, è facile da installare, implementare e mettere a punto nuovi servizi.
Velocità più elevata:
sistema di calcolo distribuito può avere più potenza di calcolo dei computer, il che rende una velocità di elaborazione più veloce di altri sistemi.
Sistemi Aperti:
Poiché si tratta di un sistema aperto che può essere accesso locale o remoto al servizio.
Prestazioni più elevate:
cluster di rete di computer centralizzati confrontati per fornire prestazioni più elevate (e un prezzo migliore).
Lo svantaggio di calcolo distribuito
Risoluzione dei problemi ::
Risoluzione dei problemi e diagnosticare il problema.
Software:
supporto software Meno è il principale svantaggio dei sistemi di calcolo distribuito.
rete:
Problemi di infrastrutture di rete, tra cui: problemi di trasmissione, ad alto carico, le informazioni si perde e così via.
Sicurezza:
sistema di calcolo caratteristiche dello sviluppo del sistema permette distribuiti è vulnerabile a rischi per la sicurezza e la condivisione di problemi di dati.
Che cosa è NoSQL?
NoSQL, si riferisce a un database non relazionale. NoSQL è a volte indicato anche come abbreviazione non solo per SQL, è diverso dal tradizionale sistema di gestione di database di database relazionali collettivamente.
NoSQL per la memorizzazione dei dati su larga scala. (Come Google o Facebook trilione di bit di dati al giorno raccolti per i loro utenti). Questi tipi di memorizzazione dati non richiede uno schema fisso, nessuna operazione supplementare può essere esteso lateralmente.
Perché NoSQL?
Oggi siamo in grado di essere la piattaforma di terze parti: si può facilmente accedere e recuperare i dati (come Google, Facebook, ecc). le informazioni personali degli utenti, il social networking, l'ubicazione, i dati generati dagli utenti e utente accede è aumentato esponenzialmente. Se vogliamo mineraria questi dati utente, database SQL che non è adatto per queste applicazioni, e lo sviluppo di dati NoSQL è ben in grado di gestire questi dati di grandi dimensioni.
Esempi
reti socializzato:
record separati: UserID, first_name, cognome, età, genere, ...
Compito: Trova tutti gli amici di amici di amici di amici ... di un determinato utente.
pagina di Wikipedia:
Combinazione di dati strutturati e non strutturati
Compito: Recupera tutte le pagine riguardanti atletica di estate olimpica prima del 1950.
RDBMS vs NoSQL
RDBMS
- La struttura altamente organizzata dei dati
- Lingua Structured Query (SQL) (SQL)
- Dati e rapporti sono memorizzati in una tabella separata.
- Data Manipulation Language, Data Definition Language
- Consistenza Strict
- servizi di base
NoSQL
- Rappresenta non solo SQL
- Nessun linguaggio di query dichiarativo
- Nessun modello predefinito
- Coppia di valori, la memorizzazione della colonna, archiviazione documenti, grafica, dati - Chiave
- la coerenza eventuale, piuttosto che proprietà ACID
- Dati imprevedibile e non strutturati
- Teorema CAP
- Alte prestazioni, alta disponibilità e scalabilità
NoSQL Breve storia
NoSQL Il termine la prima volta nel 1998, è un peso leggero di sviluppo Carlo Strozzi, open source, non fornisce funzionalità di database relazionale SQL.
Nel 2009, di Last.fm Johan Oskarsson ha avviato una discussione su open source database distribuito [2], Eric Evans da Rackspace nuovo proposto il concetto di NoSQL, poi il NoSQL si riferisce principalmente alla non-relazionali, distribuito, non forniscono ACID modelli di progettazione di database.
Nel 2009 ad Atlanta "no: SQL (est)" seminario è una pietra miliare, con lo slogan "selezionare divertimento, profitto da real_world dove relazionale = false;". Pertanto, NoSQL spiegazione più comune è che "non associato di tipo", ha sottolineato i vantaggi dei valori-chiave di negozi e banche dati del documento, piuttosto che mera RDBMS opposizione.
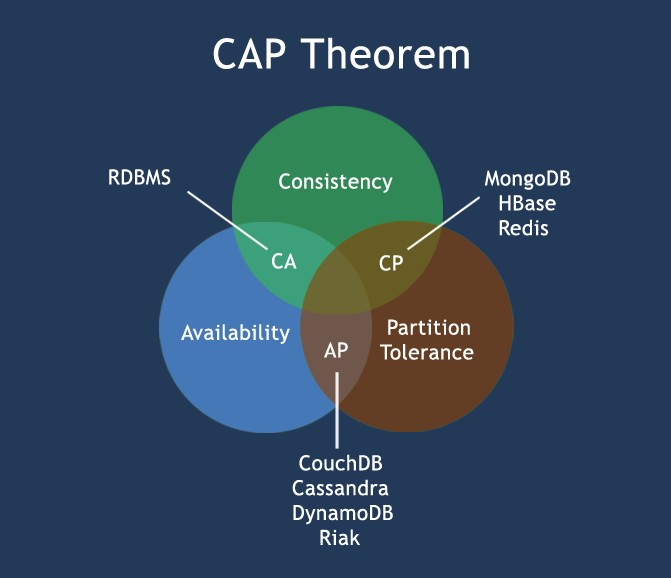
CAP Teorema (PAC teorema)
In informatica, CAP Teorema (teorema cap), conosciuto anche come Brewer Teorema (teorema di birra), che ha sottolineato che per un sistema di calcolo distribuito, non può soddisfare contemporaneamente i seguenti tre punti:
- Consistenza (Consistenza) (tutti i nodi hanno gli stessi dati allo stesso tempo)
- Disponibilità (Availability) (verificare che ogni richiesta ha una risposta a prescindere dal successo o il fallimento)
- Tolleranza Partizione (tolleranza Partizione) (perdita di sistema o guasto di qualsiasi delle informazioni non influenza il funzionamento continuo del sistema)
teoria nucleo PAC è: un sistema distribuito non può soddisfare contemporaneamente la consistenza, la disponibilità, la tolleranza ai guasti, e partizionare questi tre requisiti in grado di soddisfare solo due bel po '.
Così, secondo i principi del database PAC NoSQL nel CA soddisfare il principio, per incontrare e soddisfare i principi di CP principio AP tre categorie:
- CA - un unico punto di gruppo si incontrano coerenza, la disponibilità del sistema, la scalabilità, di solito con meno potenti.
- CP - incontrare consistenza, tollera la partizione delle prestazioni del sistema in genere non è particolarmente elevato.
- AP - incontrano la disponibilità, la tolleranza della partizione del sistema, di solito requisiti di conformità possono essere inferiori.
NoSQL vantaggi / svantaggi
vantaggi:
- - Elevata scalabilità
- - Distributed Computing
- - Basso costo
- - La flessibilità architettonica, dati semi-strutturati
- - Nessun rapporto complicato
svantaggi:
- - C'è standardizzazione
- - Funzione di ricerca Limited (finora)
- - Accordo finale non è un programma intuitivo
BASE
BASE: Fondamentalmente disponibili, Soft-stato, alla fine coerente. Definito da Eric Brewer.
teoria nucleo PAC è: un sistema distribuito non può soddisfare contemporaneamente la consistenza, la disponibilità, la tolleranza ai guasti, e partizionare questi tre requisiti in grado di soddisfare solo due bel po '.
BASE è un database NoSQL è in genere debole, la disponibilità e la coerenza dei requisiti principali:
- Fondamentalmente Availble - di base disponibili
- Soft-stato - soft stato / transazione flessibile. "Stato soft" può essere inteso come "nessuna connessione", e "stato Hard" è "orientato alla connessione" in
- Eventuale Coerenza - eventuale consistenza eventuale coerenza è l'obiettivo finale di ACID.
ACID vs BASE
| ACID | BASE |
|---|---|
| Atomica (A tomicity) | Basic può essere utilizzato (B asically A vailable) |
| Consistenza (C OERENZA) | stato morbido / servizi flessibili (S stato oft) |
| Isolamento (I consolazione) | consistenza Eventuale (E consistenza ventual) |
| Persistente (D urable) |
la classificazione del database NoSQL
| tipo | alcuni rappresentanti | caratteristica |
| negozi colonna | HBase cassandra Hypertable | Come suggerisce il nome, è memorizzato in colonne di dati. La più grande caratteristica è facile da immagazzinare dati strutturati e semi-strutturati, facile da fare la compressione dei dati, per avere un vantaggio molto grande per IO di una o più colonne di una query. |
memorizzazione documenti | MongoDB CouchDB | archiviazione dei documenti è generalmente utilizzato per memorizzare formato JSON simile, il contenuto viene memorizzato nel tipo di documento. Questo ha anche la possibilità di costruire un indice su qualche campo, per realizzare alcune delle caratteristiche di un database relazionale. |
memorizzazione di valori-chiave | Tokyo Governo / Tiranno Berkeley DB MemcacheDB Redis | È possibile verificare velocemente al suo valore con il tasto. In generale, indipendentemente dal valore formato di memorizzazione di ereditare. (Redis contiene funzionalità aggiuntive) |
Mappa della memoria | Neo4j FlockDB | Migliori relazioni negozio Graphics. Basso utilizzo di prestazioni tradizionali database relazionale per risolverlo, e il design è scomodo da usare. |
Stoccaggio oggetto | db4o versante | Attraverso sintassi del linguaggio orientato agli oggetti è simile al funzionamento della banca dati, accessibile attraverso l'oggetto dati. |
database XML | Berkeley DB XML BaseX | Efficiente memorizzazione dei dati XML e supporta la sintassi di query XML interno, come ad esempio XQuery, XPath. |
Chi utilizza
Ci sono già molte aziende utilizzano NoSQL:- Mozilla
- adobe
- Foursquare
- Digg
- McGraw-Hill Education
- Vermont Public Radio