fetta MongoDB
Fette
Vi è un altro cluster MongoDB all'interno, la tecnologia affettare, una grande quantità di dati per soddisfare la crescente domanda di MongoDB.
Quando MongoDB per memorizzare grandi quantità di dati, una macchina può essere sufficiente per memorizzare i dati, potrebbe essere insufficiente per fornire una lettura accettabile e scrivere il throughput. A questo punto, si può suddividere i dati su più macchine, in modo che il sistema di database in grado di memorizzare ed elaborare più dati.
Perché fetta
- Copia tutto le operazioni di scrittura per il nodo primario
- Ritardo dati sensibili nella master query
- Un unico insieme di copia è limitata a 12 nodi
- Quando l'enorme volume di richieste viene visualizzato quando la memoria.
- carenza disco locale
- espansione verticale è costoso
fetta MongoDB
La figura seguente mostra l'uso della fetta struttura grappolo nella distribuzione MongoDB:
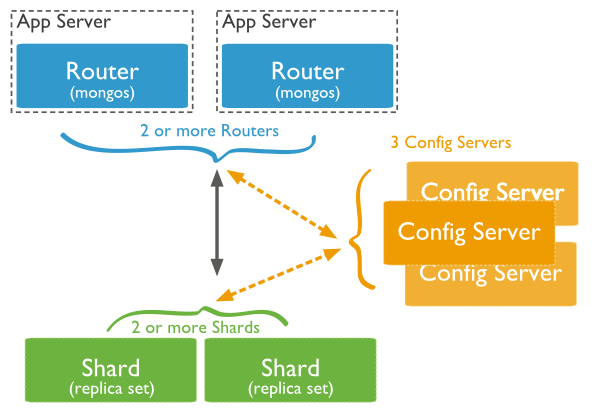
L'immagine sopra ha le seguenti tre componenti principali:
- Shard:
Utilizzato per memorizzare il blocco di dati effettivi, l'ambiente di produzione vera e propria, un ruolo del server frammento può impostare alcune macchine Relica impostato un impegno per evitare che il punto singolo host di guasto
- Config Server:
esempio mongod, memorizza l'intero ClusterMetadata, comprese le informazioni sul blocco.
- Router Query:
Il frontale del percorso, per cui l'accesso client, e l'intero cluster sembrano un unico database di applicazioni front-end in grado di utilizzare in modo trasparente.
Esempi di frammentazione
porte fabric fetta sono distribuiti come segue:
Shard Server 1:27020 Shard Server 2:27021 Shard Server 3:27022 Shard Server 4:27023 Config Server :27100 Route Process:40000
Fase uno: Inizia Shard Server
[root@100 /]# mkdir -p /www/mongoDB/shard/s0 [root@100 /]# mkdir -p /www/mongoDB/shard/s1 [root@100 /]# mkdir -p /www/mongoDB/shard/s2 [root@100 /]# mkdir -p /www/mongoDB/shard/s3 [root@100 /]# mkdir -p /www/mongoDB/shard/log [root@100 /]# /usr/local/mongoDB/bin/mongod --port 27020 --dbpath=/www/mongoDB/shard/s0 --logpath=/www/mongoDB/shard/log/s0.log --logappend --fork .... [root@100 /]# /usr/local/mongoDB/bin/mongod --port 27023 --dbpath=/www/mongoDB/shard/s3 --logpath=/www/mongoDB/shard/log/s3.log --logappend --fork
Fase due: Avviare il server di configurazione
[root@100 /]# mkdir -p /www/mongoDB/shard/config [root@100 /]# /usr/local/mongoDB/bin/mongod --port 27100 --dbpath=/www/mongoDB/shard/config --logpath=/www/mongoDB/shard/log/config.log --logappend --fork
Nota: Qui possiamo iniziare come il servizio mongodb ordinaria come inizio, non c'è bisogno di aggiungere parametri -shardsvr e configsvr. Perché il ruolo di questi due parametri è quello di cambiare la porta di partenza, in modo che possiamo essere la porta di auto-designato.
Fase tre: avviare il processo di percorso
/usr/local/mongoDB/bin/mongos --port 40000 --configdb localhost:27100 --fork --logpath=/www/mongoDB/shard/log/route.log --chunkSize 500
parametri di avvio Mongos, chunksize questo viene utilizzato per specificare le dimensioni del pezzo, l'unità è MB, la dimensione predefinita è 200 MB.
Fase quattro: configurazione Sharding
Avanti, usiamo MongoDB Shell Accedere a Mongos, aggiungere nodi Shard
[root@100 shard]# /usr/local/mongoDB/bin/mongo admin --port 40000
MongoDB shell version: 2.0.7
connecting to: 127.0.0.1:40000/admin
mongos> db.runCommand({ addshard:"localhost:27020" })
{ "shardAdded" : "shard0000", "ok" : 1 }
......
mongos> db.runCommand({ addshard:"localhost:27029" })
{ "shardAdded" : "shard0009", "ok" : 1 }
mongos> db.runCommand({ enablesharding:"test" }) #设置分片存储的数据库
{ "ok" : 1 }
mongos> db.runCommand({ shardcollection: "test.log", key: { id:1,time:1}})
{ "collectionsharded" : "test.log", "ok" : 1 }
Fase cinque: Nel codice di programma senza cambiare molto, un collegamento diretto in conformità con il database Mongo ordinaria come interfaccia di accesso al database per collegare 40.000