NoSQL에 프로필
"뿐만 아니라 SQL"을 의미되는 NoSQL (NoSQL에 =뿐만 아니라 SQL).
네트워크에있는 현대 컴퓨팅 시스템에서 대량의 데이터를해야합니다.
이러한 데이터는 처리하는 관계형 데이터베이스 관리 시스템 (RDMBSs)의 큰 부분이다. 데이터 모델링 및 응용 프로그램 프로그래밍 쉽게 1970 EFCodd의 제안 관계형 모델 종이 "큰 공유 데이터 뱅크에 대한 데이터의 관계형 모델".
검증 된 관계 모델을 적용함으로써 지금까지 예상되는 이점 이상으로, 클라이언트 - 서버 프로그램에 매우 적합하고, 오늘날 네트워크 비즈니스 애플리케이션 지배적 기술에 저장된 구조화 된 데이터이다.
되는 NoSQL 데이터베이스는 일찍에 더욱 더의 발전 추세는 2009 년 상승 것을 제안하고, 새로운 혁명 운동이다. 관계형 데이터베이스의 압도적 인 용도에 대해, 비 관계형 데이터 저장 장치의 사용을 촉진되는 NoSQL 지지자,이 개념은 의심 할 여지없이 새로운 사고를 주입한다.
규칙 ACID를 수행하는 관계형 데이터베이스
그것은 다음과 같은 네 가지 특성을 갖고, 영어 트랜잭션은 트랜잭션이며, 거래의 실제 매우 유사
1, 쉬운 원자는 이해하기 <BR> A (자성) 원자는, 트랜잭션의 모든 작업 중 하나를 모두 수행하거나하지 않는 것이 수행 트랜잭션이만큼이 모든 작업의 성공을위한 조건이 성공적으로 거래입니다 작업은 전체 트랜잭션이 실패 롤백 할 필요가 실패합니다.
2) × 100 위안 예금 계좌를 B로 1)는 A 100 위안 계정을 가지고 : 이러한 은행 송금, B에 대한 100 위안 계정에서 계좌 이체로, 두 단계로 나누어진다. 첫 번째 단계, 두 번째 단계가 실패 돈 든 것 1백위안 이하 완료된 경우이 두 단계는 서로 함께 여부 중 완료 완료된다.
2, C (일관성) 일관성로 <br> 일관성은 원래 데이터베이스의 일관성 제약 조건을 변경되지 않습니다 트랜잭션을 실행, 일관성있는 상태로 데이터베이스에있다가, 이해하기 비교적 쉽다.
이러한 + B = 10 기존 무결성 제약, 트랜잭션이 변경되면, 우리는 그렇지 않으면 트랜잭션이 실패 트랜잭션의 후단 여전히 + B = 10를 만족되도록, (B)를 변경한다.
3, I (격리)는 소위 <BR> 독립, 그것을 트랜잭션 데이터가 다른 커밋되지 않은 트랜잭션만큼 수정되는 다른 트랜잭션에 액세스 할 경우 독립 서로 동시 트랜잭션에 영향을 미치지 않음을 의미 액세스 데이터가 커밋되지 않은 트랜잭션의 영향을받지 않습니다.
예를 들어, B에 대한 100 위안 계정에서 기존 거래 계좌는 B가 자신의 계정을 선택하면 새로 추가 된 100위안를 볼 수 없습니다. 완료되지 않은이 거래의 경우, 전송이있다.
트랜잭션, 그것은 영구적으로 데이터베이스에 저장됩니다 편집, 다운 타임이 발생하더라도 손실되지 않습니다 커밋하면 4, D (내구성) 지속성 지속성로 <br> 의미한다.
분산 시스템
분산 시스템 (분산 시스템) 소프트웨어 구성 요소를 여러 컴퓨터 및 컴퓨터 네트워크로 구성된 통신 접속 (로컬 네트워크 또는 광역 네트워크).
분산 시스템은 네트워크 소프트웨어 시스템의 상단에 내장되어 있습니다. 이 때문에 정확하게 소프트웨어, 응집력 및 투명도가 높은 분산 시스템의 특징이다.
따라서, 네트워크 및 분산 시스템보다 높은 레벨의 소프트웨어 (특히, 오퍼레이팅 시스템)보다는 하드웨어 차이.
PC와 워크 스테이션, LAN과 WAN들과 같은 분산 시스템과 같은 다양한 플랫폼에 적용 할 수있다.
분산 컴퓨팅의 장점
신뢰성 (내결함성)
분산 컴퓨팅 시스템의 중요한 장점은 신뢰성이있다. 서버의 나머지 부분에 영향을 미치지 않는 서버에 오류가 발생합니다.
확장 성 :
필요에 따라 분산 컴퓨팅 시스템에서 더 많은 기계를 추가 할 수 있습니다.
자원 공유 :
데이터를 공유 뱅킹과 같은 응용 프로그램, 예약 시스템에 필수적이다.
유연성 :
시스템은 매우 유연하기 때문에, 설치 구현하고 새로운 서비스를 디버깅하기 쉽다.
빠른 속도 :
분산 컴퓨팅 시스템은 다른 시스템보다 더 빠른 처리 속도 만드는 컴퓨터 이상의 컴퓨팅 파워를 가질 수있다.
개방형 시스템 :
이 서비스에 로컬 또는 원격으로 액세스 할 수있는 개방형 시스템이기 때문이다.
높은 성능 :
중앙 컴퓨터 네트워크 클러스터 성능 (더 나은 가격)에 비해 더 제공 할 수있다.
분산 컴퓨팅의 단점
문제 해결 ::
문제를 해결하고 문제를 진단합니다.
소프트웨어 :
이하 소프트웨어 지원은 분산 컴퓨팅 시스템의 주요 단점이다.
네트워크 :
를 포함하여 네트워크 인프라 구조의 문제점 : 전송 문제, 높은 부하 정보 등등 잃고있다.
보안 :
시스템의 발전 특성있게 분산 컴퓨팅 시스템 보안 위험 데이터의 공유 문제에 취약하다.
NoSQL에 무엇입니까?
되는 NoSQL은 비 관계형 데이터베이스를 의미한다. NoSQL이 때로는 또한뿐만 SQL의 약어로 지칭되며, 이는 집단적으로 기존 데이터베이스 관리 시스템 관계형 데이터베이스와 다르다.
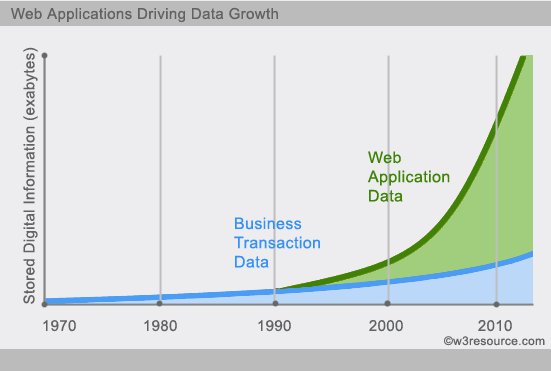
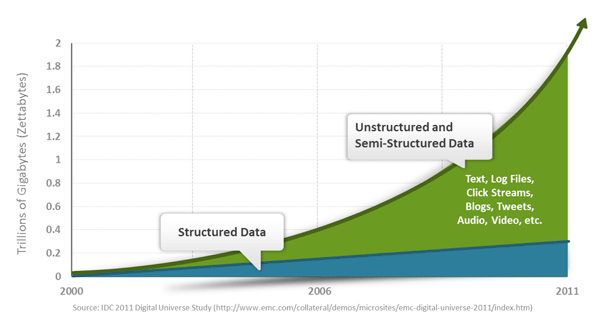
NoSQL에 대규모 데이터를 저장. (이러한 구글이나 페이스 북 사용자들에 대해 수집 하루에 데이터의 조 비트 등). 데이터 저장소의 이러한 유형의 고정 된 패턴을 필요로하지 않고, 여분의 작업이 측 방향 연장 될 수 없다.
왜 NoSQL에?
당신은 쉽게 (등 구글, 페이스 북 등) 데이터에 액세스하고 가져올 수 : 오늘 우리는 제 3 자 플랫폼이 될 수 있습니다. 사용자의 개인 정보, 소셜 네트워킹, 위치, 사용자가 생성 한 데이터 및 사용자 로그는 기하 급수적으로 증가하고있다. 우리는 이러한 사용자 데이터 마이닝, 이러한 응용 프로그램에 적합하지 않은 SQL 데이터베이스 및되는 NoSQL 데이터베이스의 개발을하려는 경우 이러한 대용량 데이터를 처리 할 잘 할 수있다.
예
사회화 네트워크 :
별도의 기록 : 사용자 ID, FIRST_NAME, LAST_NAME, 연령, 성별, ...
태스크 :의 ... 특정 사용자의 친구의 친구의 친구의 모든 친구를 찾아보세요.
위키 백과 페이지 :
정형 및 비정형 데이터의 조합
작업은 : 1950 전에 여름 올림픽의 육상에 대한 모든 페이지를 검색합니다.
NoSQL에 대 RDBMS
RDBMS
- 데이터의 고도로 조직화 된 구조
- 구조화 조회 언어 (SQL) (SQL)
- 데이터와의 관계는 별도의 테이블에 저장됩니다.
- 데이터 조작 언어, 데이터 정의 언어
- 엄격한 일관성
- 기본 서비스
NoSQL에
- 그냥 SQL을하지 나타냅니다
- 어떤 선언적 쿼리 언어 없음
- 미리 정의 된 패턴 없음
- 키 - 값 쌍, 열 저장, 문서 저장, 그래픽, 데이터베이스
- 최종 일관성보다는 ACID 속성
- 예측할 수없는 및 비정형 데이터
- CAP 정리
- 고성능, 고 가용성 및 확장 성
NoSQL에 대한 간략한 역사
NoSQL에이 용어가 처음 1998 년에 등장, 경량 카를로 Strozzi 개발, 오픈 소스, SQL 관계형 데이터베이스 기능을 제공하지 않습니다.
2009 년, Last.fm의 요한 Oskarsson이, 랙 스페이스에서 에릭 에반스가 다시되는 NoSQL의 개념을 제안 하였다 [2] 오픈 소스 분산 데이터베이스에 대한 토론을 시작, 다음 NoSQL에 주로 분포, 비 관계형, 제공하지 않습니다를 참조 ACID 데이터베이스 디자인 패턴.
2009 년 애틀랜타 "아니오 : SQL (동쪽)"세미나는 슬로건과 "real_world에서 재미, 이익을 선택할 경우 = 거짓 관계;", 이정표이다. 따라서, NoSQL에 가장 일반적인 설명은 "비 수반 유형을"오히려 단순한 야당 RDBMS보다는 키 - 값 저장 및 문서 데이터베이스의 장점을 강조한다는 것입니다.
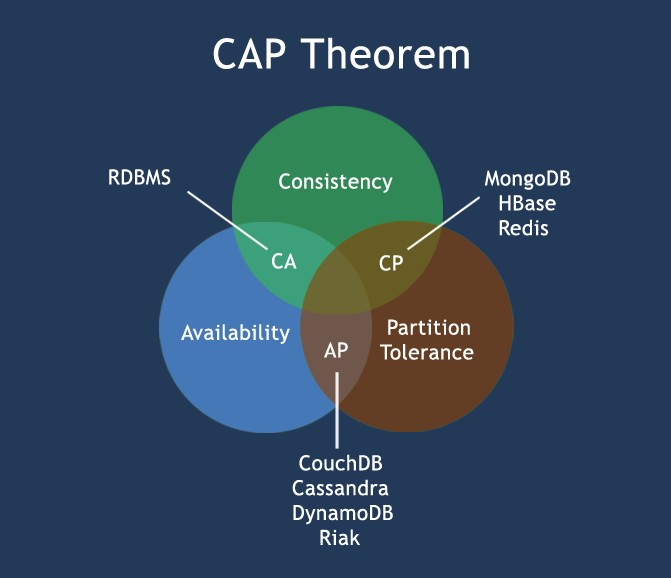
CAP 정리 (CAP 정리)
컴퓨터 과학, 또한 분산 컴퓨팅 시스템에 동시에 다음의 세 가지 점을 충족 할 수 없다는 지적 브루 정리 (브루어의 정리)라고도 CAP 정리 (CAP 정리) :
- 일관성 (일관성) (모든 노드들이 동시에 동일한 데이터를 가지고)
- 가용성 (가용성) (모든 요청에 관계없이 성공 또는 실패의 응답이 있는지 확인)
- 파티션 공차 (분배 오차 ()의 정보 중 어느 하나의 시스템 손실 또는 오류가 시스템의 계속 운전에 영향을 미치지 않음)
CAP 코어 이론은 : 분산 시스템 동시에 일관성, 가용성 내결함성을 만족하고, 두 좋지만 만날 수 이들 세 가지 요구를 분할 할 수 없습니다.
따라서, CA에 CAP되는 NoSQL 데이터베이스의 원리에 따른 CP의 AP 원리 세 종류의 원리를 충족 만족하는 원리를 충족 :
- CA - 일반적으로 덜 강력한에 클러스터 대회의 일관성, 시스템 가용성, 확장 성, 단일 지점.
- CP - 시스템 성능의 파티션을 견딜 것이다 일관성을 충족 특히 일반적으로 높지 않다.
- AP는 - 가용성 시스템의 파티션 공차를 충족 일반적 적합성 요건은 낮을 수있다.
NoSQL에 장점 / 단점
장점 :
- - 높은 확장 성
- - 분산 컴퓨팅
- - 낮은 비용
- - 건축 유연성, 반 구조화 된 데이터
- - 복잡한 관계 없음
단점 :
- - 아니 표준화가 없습니다
- - 제한 검색 기능 (지금까지)
- - 최종 계약은 직관적 인 프로그램이 아닙니다
BASE
BASE : 기본적으로 사용 가능, 소프트 상태, 결국 일관성. 에릭 브루 정의.
CAP 코어 이론은 : 분산 시스템 동시에 일관성, 가용성 내결함성을 만족하고, 두 좋지만 만날 수 이들 세 가지 요구를 분할 할 수 없습니다.
BASE가되는 NoSQL 데이터베이스 가용성과 원칙 요구 사항의 일관성을 위해 일반적으로 약한입니다 :
- 기본적으로 availble을 - 사용 가능한 기본
- 소프트 상태 - 부드러운 상태 / 유연한 거래. "소프트 상태"가 "연결되지"및 "하드 상태"로 이해 될 수있다 "연결 지향"에서
- 최종 일관성 - 최종 일관성 최종 일관성은 ACID의 궁극적 인 목표입니다.
BASE 대 ACID
| ACID | BASE |
|---|---|
| 원자 (A tomicity) | 기본을 사용할 수있다 (B asically로만 제공) |
| 일관성 (C의 onsistency) | 소프트 상태 / 유연한 서비스 (S 자주 상태) |
| 절연 (나는 solation) | 최종 일관성 (E ventual 일관성) |
| 영구 (D의 urable) |
되는 NoSQL 데이터베이스 분류
| 유형 | 일부 대표 | 특징 |
| 열 저장 | HBase를 카산드라 Hypertable | 이름이 암시 하듯이, 그것은 데이터 열에 저장된다. 가장 큰 특징은 질의의 칼럼 또는 칼럼의 IO에 대해 매우 큰 장점을 갖고, 데이터 압축을 수행하기 쉬운 구조 및 반 구조화 된 데이터를 저장하기 쉽다. |
문서 저장 | MongoDB를 CouchDB를 | 문서 저장은 일반적으로 유사한 JSON 포맷을 저장하는 데 사용되는 콘텐츠는 문서 형태로 저장된다. 이것은 또한 관계형 데이터베이스의 일부 기능을 달성하기 위해, 일부 필드 인덱스를 구축 할 수있는 기회를 갖는다. |
키 - 값 저장 | 도쿄 내각 / 폭군 버클리 DB MemcacheDB 레디 스 | 빠르게 키 값을 확인할 수 있습니다. 일반적으로, 상관없이 저장 형식 값 상속한다. (레디 스 추가 기능이 포함되어 있습니다) |
지도 메모리 | Neo4J FlockDB | 베스트 저장소 그래픽 관계. 전통적인 관계형 데이터베이스 성능의 낮은 사용을 해결하기 위해, 상기 설계는 사용이 불편하다. |
개체 저장 | db4o는 VERSANT | 객체 지향 언어 구문을 통해 데이터 오브젝트에 의해 액세스되는 데이터베이스의 동작과 유사하다. |
XML 데이터베이스 | 버클리 DB XML BaseX | 효율적인 XML 데이터 저장과는 XQuery를, XPath는 내부 XML 쿼리 구문을 지원합니다. |
누가 사용
되는 NoSQL을 사용하여 이미 많은 회사가있다 :- 구글
- 페이스 북
- 모질라
- 어도비 벽돌
- 정사각형
- 링크드 인
- 디그
- McGraw 언덕 교육
- 버몬트 퍼블릭 라디오