Pythonは中国のコーディング
Pythonは中国のコーディング
前の章では、我々は、Python出力 "こんにちは、世界!"、英語は問題ありませんを使用する方法を学びましたしていますが、あなたは "こんにちは、世界"中国のコーディングの問題が発生する可能性が中国語の文字で出力場合。
エンコーディングが実装プロセスで指定されていない場合はPythonのファイルが与えられます。
#!/usr/bin/python print "你好,世界";
上記プログラム実行出力は、次のとおりです。
File "test.py", line 2 SyntaxError: Non-ASCII character '\xe4' in file test.py on line 2, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
文字が正しく印刷できない場合、そのように中国のエラーを読み取るときに、デフォルトのエンコード形式でPythonはエンコード形式を変更しなかった、ASCII形式です。
解決策は#上のファイルの始まりにすぎない- * -コーディング:UTF- - 8 - *リスト上または#コーディング= UTF-8。
出力は次のとおりです。
你好,世界
だから我々は、プロセスを学習再場合、コードは中国語が含まれ、あなたは、ヘッダー内のエンコーディングを指定する必要があります。
注:Python3.XソースファイルのデフォルトのUTF-8エンコーディング、それが適切にUTF-8エンコーディングを指定せずに、中国を解決できるようにします。
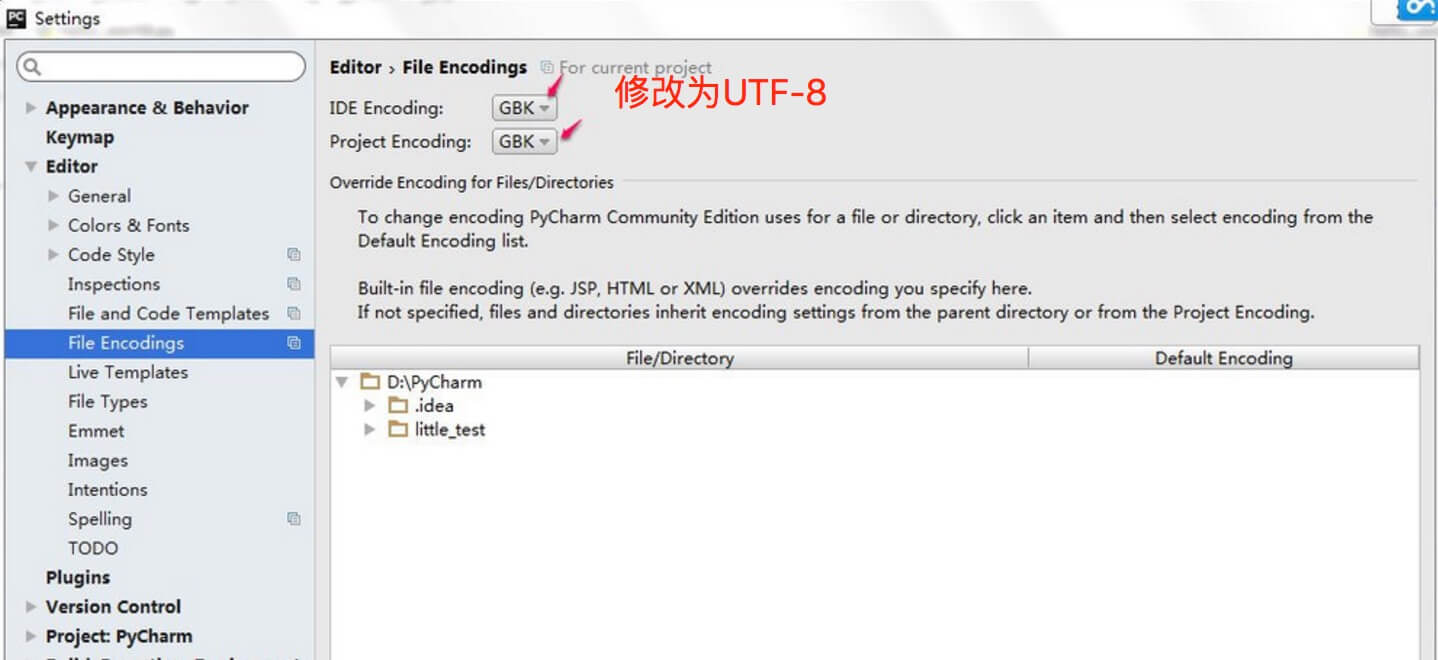
エディタを使用している場合、および優れたコードエディタを設定する必要が、そのようなPycharmの設定手順として:注意 :
- 、ファイル]> [設定]を入力し、入力ボックス内のエンコーディングを検索します。
- エディタ>ファイルエンコーディングを見つけ、IDEエンコード プロジェクトのエンコーディングは UTF-8に設定されています。