بيثون الترميز الصينية
بيثون الترميز الصينية
الفصول السابقة تعلمنا كيفية استخدام الناتج بيثون "مرحبا، العالم!"، الانجليزية لا توجد مشكلة، ولكن إذا كنت إخراج الحروف الصينية "مرحبا، العالم" من المرجح أن تواجه مشكلة الترميز الصينية.
سوف ملف الثعبان إذا لم يتم تحديد الترميز في عملية التنفيذ أن تعطى:
#!/usr/bin/python print "你好,世界";
إخراج تنفيذ البرنامج المذكور أعلاه هو:
File "test.py", line 2 SyntaxError: Non-ASCII character '\xe4' in file test.py on line 2, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
الثعبان في تنسيق الترميز الافتراضي هو شكل ASCII، لم تقم بتعديل تنسيق الترميز عندما لا يمكن طباعة الأحرف بشكل صحيح، لذلك عندما يقرأ خطأ الصيني.
الحل هو مجرد بداية الملف على # - * - الترميز: UTF- 8 - * - أو # الترميز = UTF-8 على القائمة.
الأمثلة (بايثون 2.0+)
# - * - الترميز: UTF-8 - * -
طباعة "مرحبا، العالم".
تشغيل المثال »
الإخراج:
你好,世界
لذلك إذا أردنا عملية إعادة التعلم، رمز يحتوي الصيني، تحتاج إلى تحديد الترميز في الرأس.
ملاحظة: Python3.X مصدر الملف الافتراضي ترميز UTF-8، لذلك يمكن إيجاد حل سليم للصينيين، دون تحديد ترميز UTF-8.
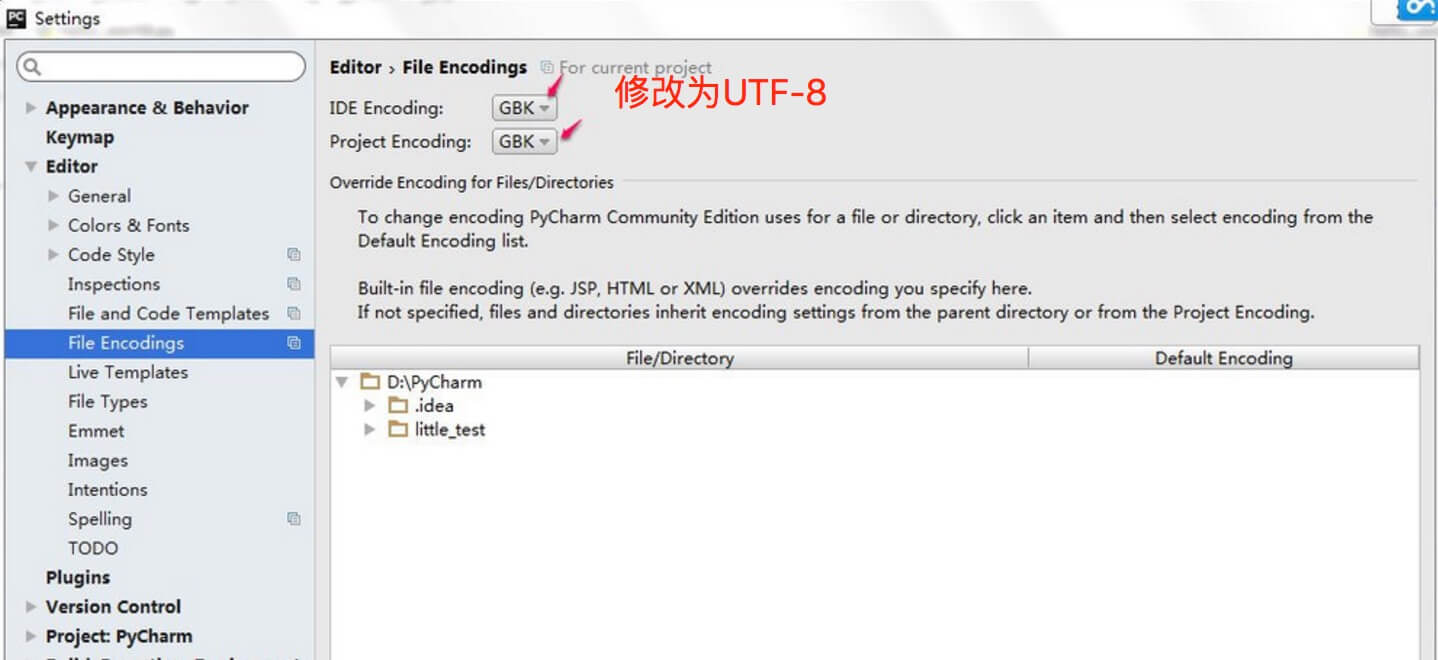
ملاحظة: إذا كنت تستخدم محرر، والحاجة إلى وضع محرر مدونة جيدة، مثل خطوات الإعداد Pycharm:
- أدخل ملف> إعدادات بحث عن الترميز في مربع الإدخال.
- العثور على محرر> ترميزات الملف، ويتم تعيين IDE ترميز مشروع ترميز إلى UTF-8.